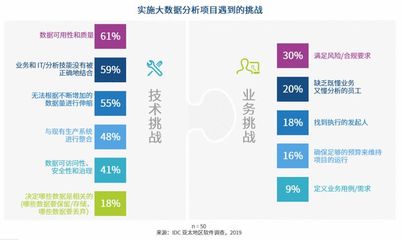
解析 AI 语音识别中的声学模型与语言模型原理
AI语音识别技术在当今社会发挥着越来越重要的作用,它能将语音准确地转换为文字,极大地便利了人们的生活与工作。其中,声学模型与语言模型是语音识别系统的关键组成部分,它们相互协作,共同致力于实现精准的语音识别。
声学模型主要负责从语音信号中提取声学特征,并将其映射到对应的音素或单词上。它基于大量的语音数据进行训练,通过学习语音信号的声学特性,建立起语音特征与语音内容之间的关系。在训练过程中,声学模型会分析语音信号的频谱、音长、音高等特征,以及不同语音单元之间的时间关系。例如,当我们说出一个单词时,声学模型会根据该单词的发音特点,识别出其对应的声学特征模式。通过对大量语音样本的学习,声学模型能够不断优化自身参数,提高对语音信号的识别准确率。常见的声学模型有隐马尔可夫模型(HMM)和深度神经网络(DNN)。隐马尔可夫模型将语音信号看作是由一系列隐藏状态(如音素)生成的可观察序列,通过对状态转移概率和观察概率的建模来识别语音。而深度神经网络则利用多层神经元对语音特征进行深度提取和分类,能够更好地捕捉语音信号的复杂模式。

语言模型则专注于处理语言的语法、语义和上下文信息,预测下一个可能出现的单词或语言单元。它基于大规模的文本数据进行训练,学习语言的统计规律和语义关系。语言模型会考虑单词之间的共现概率、语法结构以及语义相关性等因素。比如,在一个句子中,语言模型会根据前文出现的单词,预测下一个最有可能出现的单词。通过对大量文本的学习,语言模型能够建立起语言的概率分布,从而在语音识别过程中对识别结果进行合理性评估。当声学模型输出多个可能的识别结果时,语言模型会根据语言的统计规律,计算每个结果的概率得分,选择概率最高的结果作为最终的识别输出。常见的语言模型有n-gram模型和神经网络语言模型。n-gram模型基于n个连续单词的共现概率来估计语言的概率分布,是一种较为简单但有效的语言模型。神经网络语言模型则利用神经网络对语言进行建模,能够更好地处理长距离依赖和语义信息,提高语言模型的性能。
声学模型与语言模型在语音识别中是相辅相成的关系。声学模型负责从语音信号中提取声学特征并识别语音单元,而语言模型则根据语言知识对识别结果进行筛选和优化。只有两者紧密结合,才能实现准确、自然的语音识别。例如,在一个嘈杂的环境中,声学模型可能会因为受到噪声干扰而产生一些错误的识别结果。这时,语言模型就可以根据上下文信息和语言知识,排除不合理的结果,提高识别的准确性。同样,如果声学模型的性能不佳,语言模型也难以发挥其最佳作用。因此,不断改进声学模型和语言模型的性能,以及优化它们之间的协作方式,是提高语音识别系统性能的关键。
随着人工智能技术的不断发展,声学模型和语言模型也在持续演进。深度学习的兴起为声学模型和语言模型带来了新的突破。深度神经网络在声学模型中的广泛应用,使得其能够更好地处理复杂的语音特征,大大提高了识别准确率。基于深度学习的语言模型也能够更有效地捕捉语言的语义和上下文信息,提升语言模型的性能。多模态融合技术的发展也为语音识别带来了新的机遇。将语音与图像、文本等其他模态的信息相结合,可以进一步提高语音识别的准确性和鲁棒性。例如,通过结合图像信息,语音识别系统可以更好地理解语音所处的场景,从而更准确地识别语音内容。
AI语音识别中的声学模型与语言模型原理是实现精准语音识别的核心所在。它们各自承担着不同的任务,但又相互协作,共同推动着语音识别技术不断向前发展。随着技术的持续进步,我们有理由相信语音识别将在更多领域发挥更大的作用,为人们的生活带来更多的便利和创新。